
はじめに #
ELK Stack(Beatsでログ収集、Logstashで解析、Elasticsearchで保管、Kibanaで可視化)は非常に有名です。
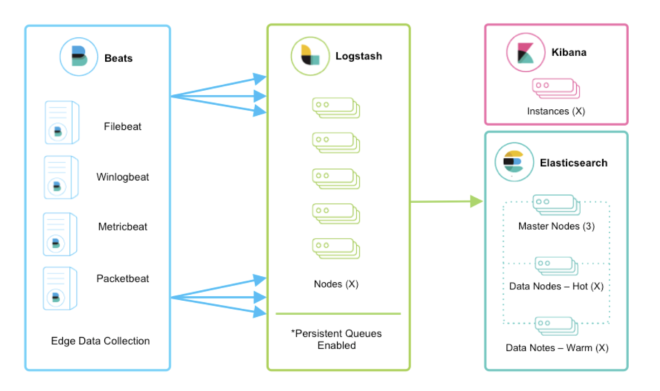
しかし、新たに「Elastic Agent」と「Data streams」がリリースされ、従来のELK Stackとは異なるログ収集方式が提供されているのでこれを使ってみます。
1. 新しいlog収集方法 #
新しい方式であるElastic Agentを使うと、従来のElastic Stackよりも簡単にログを収集できます。
- Integrationから収集したいデータソースを選ぶ
- Fleetを使ってElastic AgentにIntegrationを配布
- AgentがElasticSearchにDataを送信
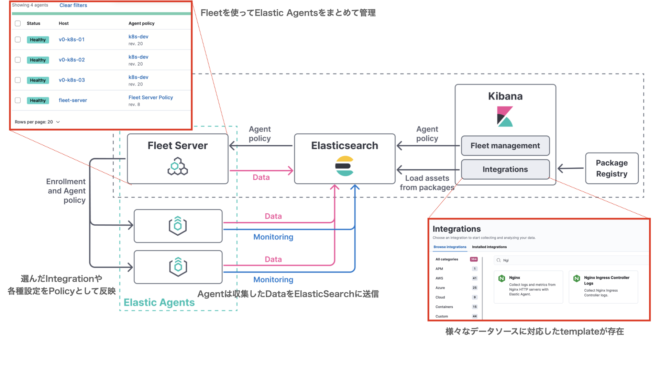
Elastic Agent
- FilebeatやMetricbeatなどのBeatsを内包する新しいログ収集ツール。
Fleet
- Elastic Agentを管理するサーバー。KibanaからElastic Agentのdeployやポリシー設定を一元管理できる。
Integration
- Syslog、NGINX、vSphere、k8s用など様々なデータソースからlogを収集するtemplateが用意されている。
- これをElastic Agentに適用することで、すぐにデータ収集が可能に
2. 検証環境の構築 #
細かく各要素を解説するには、実際に触ってみるのが早いので検証環境をdockerで構築します。
The Elastic stack (ELK) powered by Docker and Compose.
1. setupコマンドでelasticsearchの初期設定を実施
普通にcompose upする前に、elasticsearchに初期設定を入れるため、setupコンテナを起動します。
docker compose up setup
2. fleet-server付きでELKをdeploy
setupが完了したら、Fleetを構築したいのでextensions/fleet/fleet-compose.ymlを追加して compose upを実施します。
docker compose -f docker-compose.yml -f extensions/fleet/fleet-compose.yml up -d
3. login
:5601でアクセスし、デフォルトではelastic/changmeでloginすることができます。その後Fleetのページに移動しfleet-serverが登録されていればOKです。
これからFleet、Agent、Integrationsを見ていくことで、新しいログ収集の仕組みを理解していきます。
上手くいっておらずやり直すときはvolume削除 + setupから再開すること
docker compose \
-f docker-compose.yml \
-f extensions/fleet/fleet-compose.yml \
down --volumes
docker compose up setup
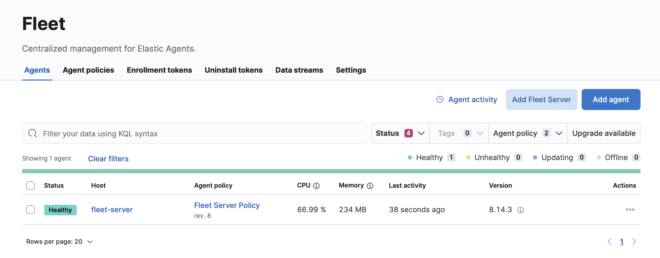
3. Fleet #
Fleetでは登録されたAgentの一覧が表示され状態や設定を確認できます。ここから新しいAgentのdeployや設定変更を実施します。
4. Elastic Agent #
Agentはデータ収集を担当しログ収集設定はPolicyを通じて行います。Policyは設定を一元管理し、簡単にAgentに適用できます。
例えばfleet-serverに適用されているPolicyを見てみると、4つのIntegrationが登録されていてdockerとsystemのログを収集していることが分かります。
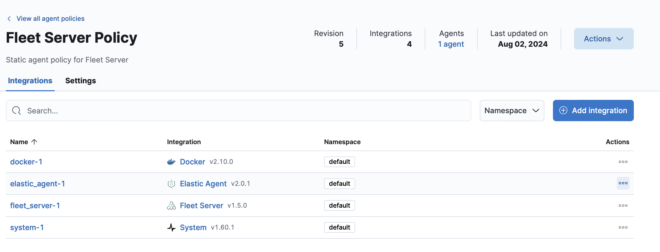
Agent(fleet-server)は今回はコンテナでdeployしていますが、通常はサーバーにinstallしたり、k8sではpodでdeployされます。 Agentの新規deployについては第2回で解説します。
5. Integrations #
Policyに適用されていたSystemのIntegrationを見てみると、auth.logやsyslogの収集を設定が実施できます。Integrationsは各種データソースに対応したtemplateになっており、自分で細かく設定をしなくてもlog収集ができるのが利点になります。
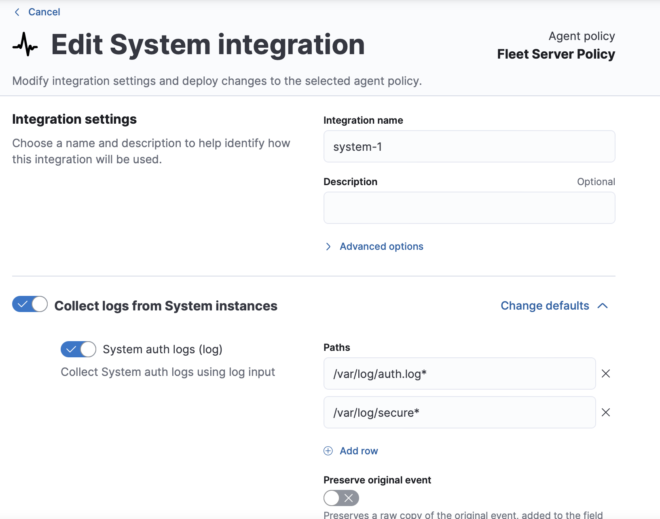
現時点だと384個のIntegrationsが用意されているので、大体のデータソースには対応しているはずです。
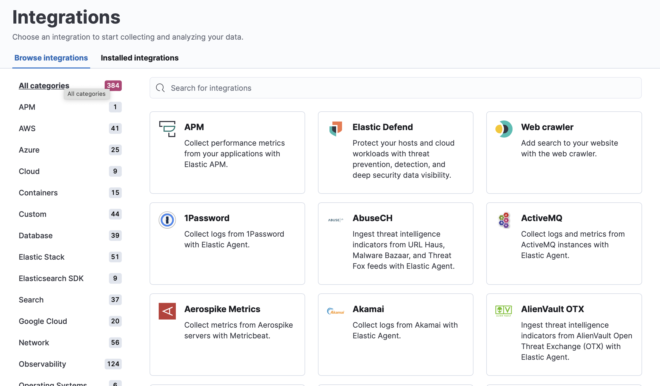
今まではlog収集用のyaml作成し、それぞれのBeatsに設定する必要がありましたがKibanaでまとめて管理できるのが便利な点です。
filebeat.inputs:
- type: tcp
host: "0.0.0.0:514"
- type: udp
host: "0.0.0.0:514"
output.elasticsearch:
hosts: [ http://elasticsearch:9200 ]
username: filebeat_internal
password: ${FILEBEAT_INTERNAL_PASSWORD}
6 logの確認(Datasteamとは) #
これらPolicyによって取得したlogはDiscoverを確認できます。
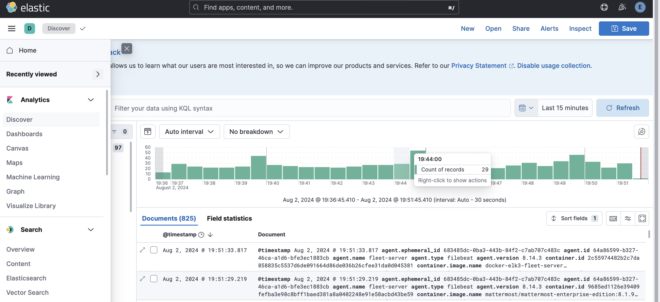
しかし今までBeatsを使っていた身からすると、Index名がlogs-*になっている点、そもそもIndex名の設定をしていないことに疑問ができます。この要因はとしてはData streamsという新たな形式でlogが保存されているためです。
7. Data Streamsとは? #
Elasticsearch 7.9以降に導入された時系列に特化したデータ取得手法です。Elastic AgentでIntegrationを使っていると自動でこの形式になります。
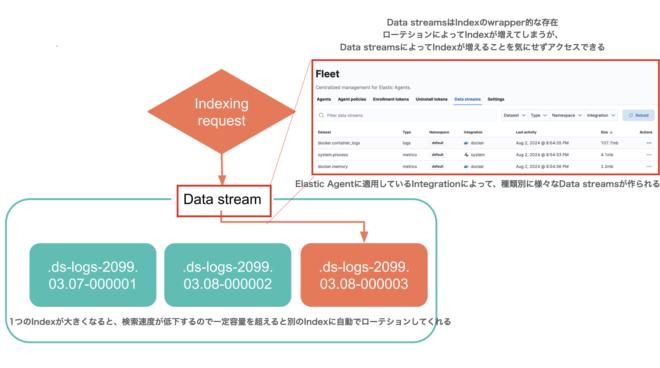
便利1. 自動でIndexをローテションしてくれる。 #
今まではIndexあたりの容量が大きくなりすぎると検索速度が低下する(50GB/shardが推奨のため)ので、定期的にIndexをsyslog-2024-03, syslog-2024-04のようにローテションする必要がありました。
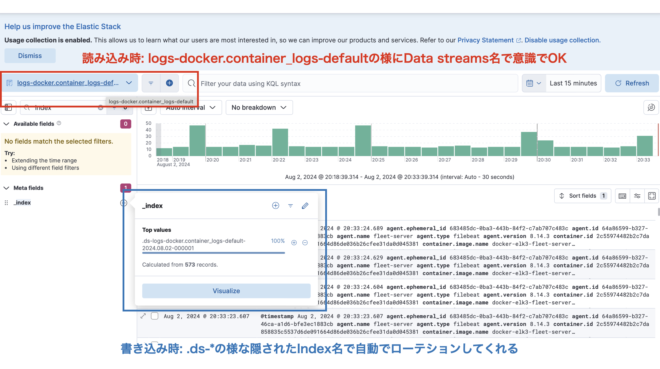
Data Streamsでは、書き込み時はローテーションを自動で実施し、読み込み時はIndexを意識せずData Streams名でOKと、Indexローテーションの仕組みを完全に隠蔽してくれるようになりました。
便利2. 自動で命名を決めてくれる。 #
Fleet → Data Streams画面をみると、type, dataset, namespaceという特徴量が定義されていることが分かります。
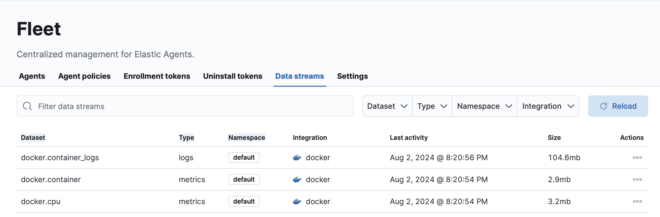
これを使ってData streamsでは命名規則が以下で統一されるようになりました。 https://www.elastic.co/guide/en/fleet/current/data-streams.html
<type>-<dataset>-<namespace>
例: logs-docker.container_logs-default
| 名前 | 説明 |
|---|---|
| type | logs-, metrics-, traces-のようにDataの種類に応じて決まった名前 |
| dataset | docker.container_logs, docker.cpuのように収集するDataの固有の名前 |
| namespace | ユーザーが好きに変更できる名前。default,prod,stgの様に環境に応じた命名をつける |
8. Data streamsを確認する。 #
Data streamsについてより詳しくなるために、実際に設定を確認してみます。
1. Data streams名の特定
Fleet → Data Streamsから取得されている、Data streamsのtype, dataset, namespaceを特定します。
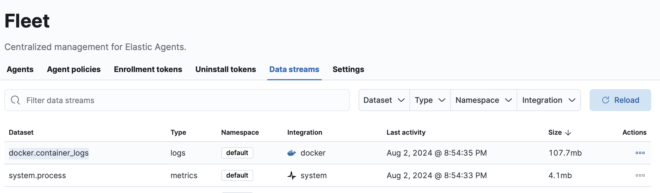
今回はdockerのlogである、logs-docker.container_logs-defaultに着目します。
2. logを見てみる
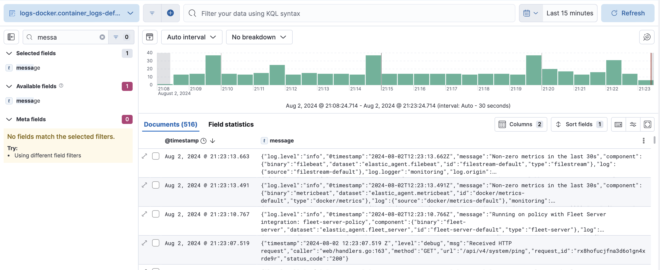
Discoverでlogs-docker.container_logs-defaultで検索をかけると、該当のData streamsのみ確認することができます。
今回elastic-agentであるfleet-serverがdockerのIntegrationを使っているので、稼働しているコンテナのlogがElasticSearchに保存されていることが分かります。
3. Data streamsの設定を見てみる
Data streamsはIntegrationsによって自動で作成されますが設定変更等したい場合が出てくると思います。その時はIndex Managmentで検索し、Data streamsのページに行くと現在の設定を見ることができます。
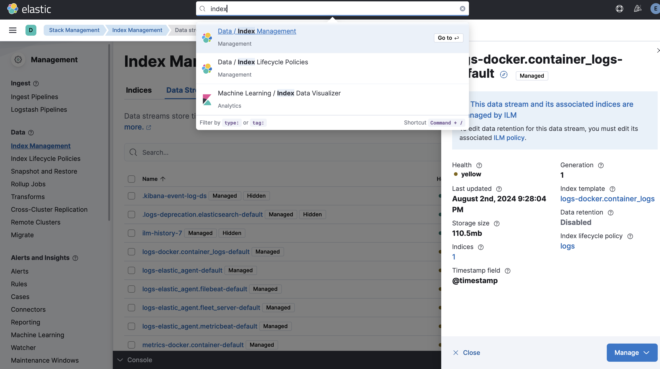
| 項目 | 説明 |
|---|---|
| Health | yellowになっていますが、これはreplica=1としているのにESのnodeが1台しかなく複製できないためです。 |
| Indices | 裏で作られているIndexの数です。 |
| Index template | shard数やreplica数などIndexに関する設定として利用しているtemplateです。 |
| Index lifecycle policy(ILM) | Indexのローテション(どのくらいの容量になったら等)の設定が定義されています。 |
4. ILMの設定を見る
Data streamsはIndexを自動でローテションしてくれますが、この設定を司っているのがIndex lifecycle policy(ILM)になります。
ILMでは様々なPhaseを指定することができます。 書き込み中のIndexは常にHot Phaseになり、defaultでは30日経過 or 50GB超過時にローテションされます。
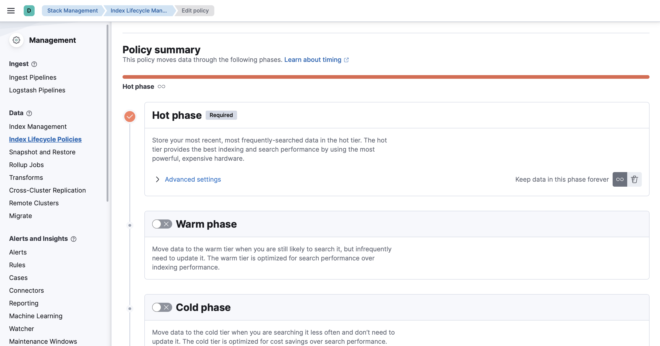
他にもローテション後Warm Phaseに移動してShard数を減らしたり、安価なストレージに移動してコストカット、そもそも削除したりできます。 これらの設定は長くなるので、第2回で紹介します。
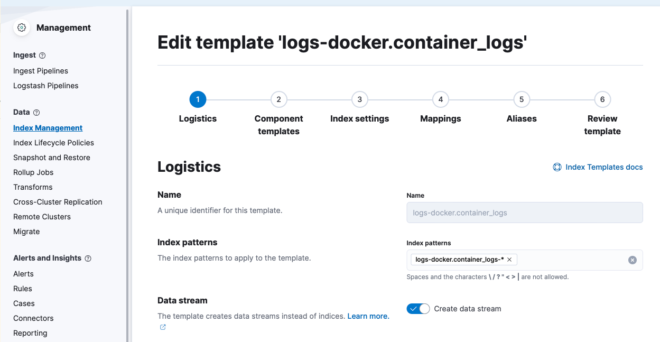
6. Index template設定を見る
Index templateではData streamsで作成されるIndexの設定(shard数、replica数や使用するILMなど)を実施することができます。
またそもそもData streamsを使用するかどうかも設定できます。
これらの設定はIntegrationsによって自動で作成されますが、これをカスタマイズする方法は第2回で解説したいと思います。
おわりに #
今回はElasticSearchの新しいlog収集方法の基本の解説と設定を見てみました。次回はAgentの追加やIntegrationの変更、Index templateのカスタマイズについて紹介します。